Если вы еще не подключили интеграцию с OpenAI, сначала выполните шаги 1–3, описанные в основной инструкции.
Assistant — это настраиваемый AI-агент на базе технологий OpenAI. Он позволяет учитывать контекст диалога, а также, в зависимости от активированных инструментов, искать информацию в заранее загруженных в него данных. Это как увеличивает количество полезных юзкейсов, так и повышает качество ответов OpenAI.
Содержание
Как это работает?
Рассмотрим на примере «Сервиса X», как устроена работа ассистента в OpenAI.
Внутренние данные: при настройке ассистента вы загружаете в него общую информацию о «Сервисе X» — документацию, базу знаний, спецификации и другие материалы. Эти данные используются для ответов на стандартные вопросы по сервису. Они не изменяются в процессе работы с пользователем.
Пример: ассистент может рассказать, как зарегистрироваться в «Сервисе X», помочь разобраться с основными возможностями или ответить на часто задаваемые вопросы, если эта информация была загружена при его настройке.
Внешний контекст: когда клиент обращается в поддержку с проблемой, ассистент использует не только загруженные внутренние данные, но и анализирует сообщения клиента с помощью активированных инструментов. Это позволяет формировать более точные и релевантные ответы.
Пример: клиент сообщает об ошибке при авторизации. Ассистент анализирует сообщения, замечает, что в указанном email есть опечатка, и формирует ответ, комбинируя внутренние данные (загруженные заранее инструкции) и внешний контекст (конкретное сообщение клиента).
Важное отличие:
Внутренние данные — информация, заранее загруженная при настройке ассистента (документация, база знаний, спецификации и другие материалы).
Внешние данные — информация, которая поступает ассистенту в процессе работы, например, вопросы пользователей в чате.
Использование внешних данных позволяет ассистенту адаптировать ответы под конкретную ситуацию, тогда как внутренние данные обеспечивают базовые знания и общий фон.
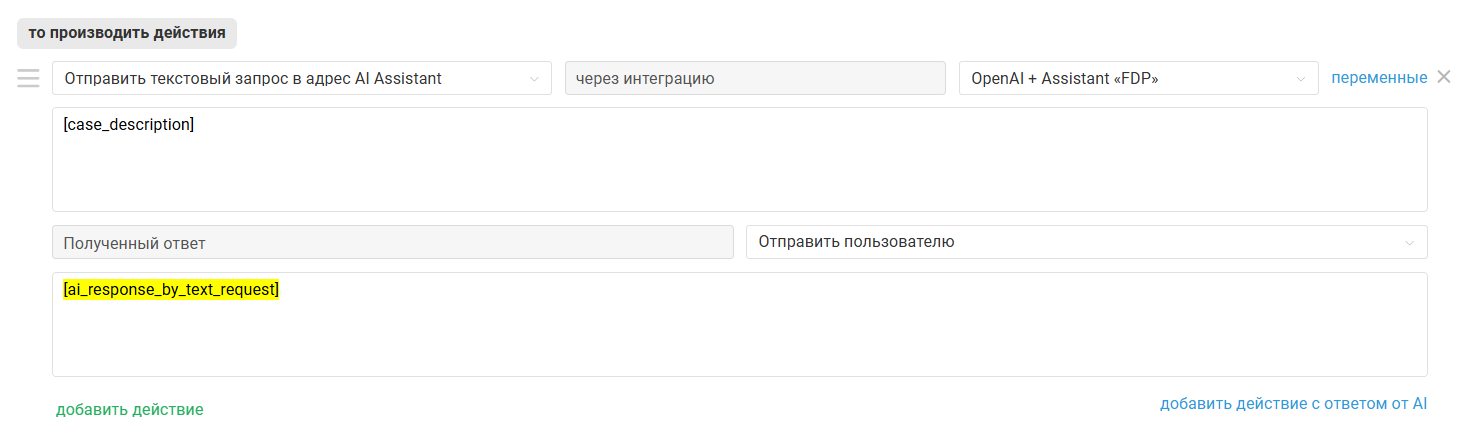
Пример работы
Мы создали правило для входящих, которое срабатывает во всех новых обращениях канала Telegram и отправляет в адрес указанного ассистента текстовый запрос [case_description]. Полученный от ассистента ответ отправляется клиенту.
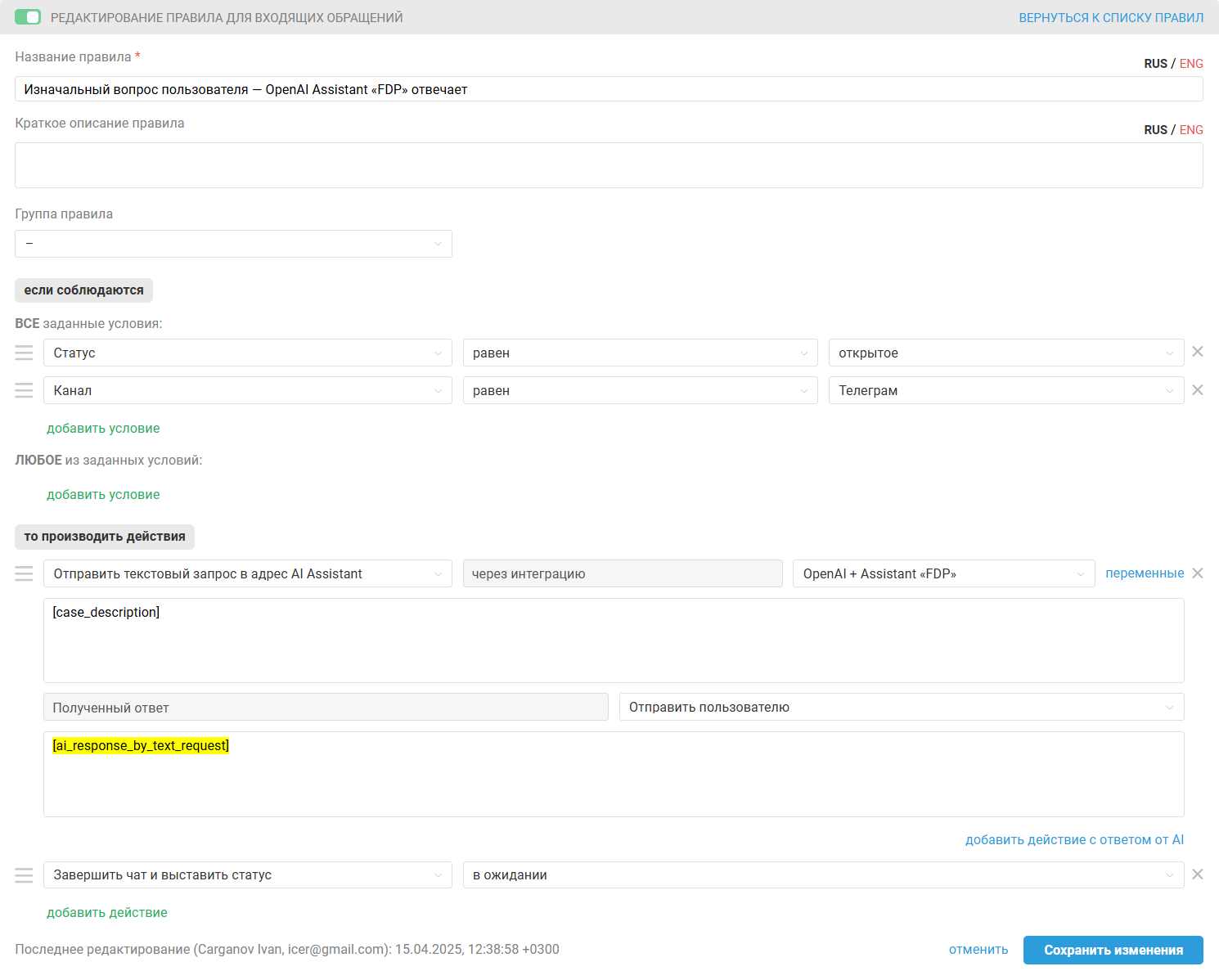
Вот как выглядит работа такого правила:
Создание, настройка и оптимизация работы ассистента в OpenAl-аккаунте осуществляются самостоятельно. Команда поддержки Омнидеска не консультирует по этим вопросам.
Если у вас нет нужных специалистов в штате или вы считаете, что настройка ассистента займет у них слишком много времени, то можете заказать платную настройку под ключ, которая включает:
— создание персонализированного ассистента в вашем OpenAI-аккаунте для выполнения функции сотрудника первой линии поддержки;
— загрузку внутренних данных (база знаний, шаблоны, обращения из вашего Омнидеск-аккаунта и другие источники), преобразование их в векторное представление и формирование базы данных ассистента;
— три бесплатных обновления внутренних данных ассистента (по предварительному запросу, не чаще одного раза в месяц);
— разовую настройку правил в вашем Омнидеск-аккаунте для корректной работы ассистента в соответствии с алгоритмом.
Стоимость услуги — 1000 евро + НДС. Для заказа настройки ассистента под ключ свяжитесь с нами.
Подключение
Для добавления функционала Assistant в уже настроенную интеграцию с OpenAI в аккаунте администратора в Омнидеске перейдите по пути Настройки → Интеграции, откройте для редактирования вашу интеграцию с OpenAI и укажите ваш Assistant ID.
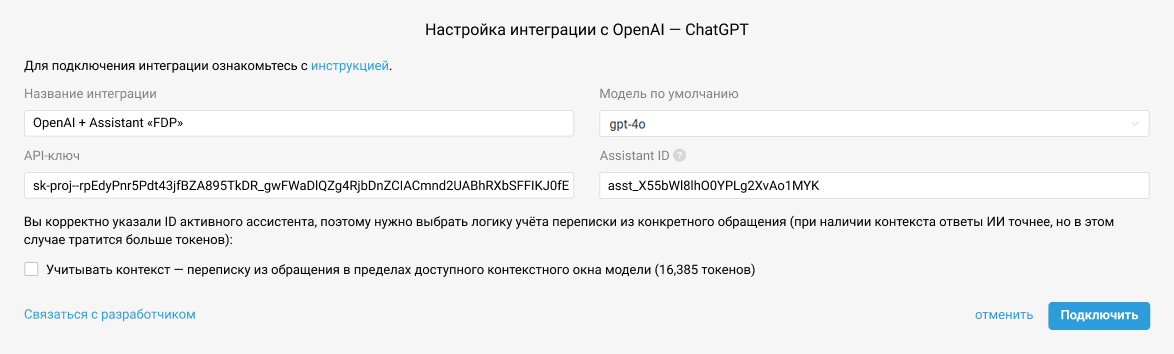
В поле «Название интеграции» укажите такое название, на которое вам будет удобно ориентироваться в дальнейшем при настройке правил автоматизации
Если интеграция с OpenAI еще не настроена, сначала выполните шаги 1–3 этой инструкции.
Как получить Assistant ID?
В аккаунте OpenAI перейдите по пути Dashboard → Assistants и скопируйте идентификатор под названием ассистента, которого вы планируете использовать в Омнидеске.
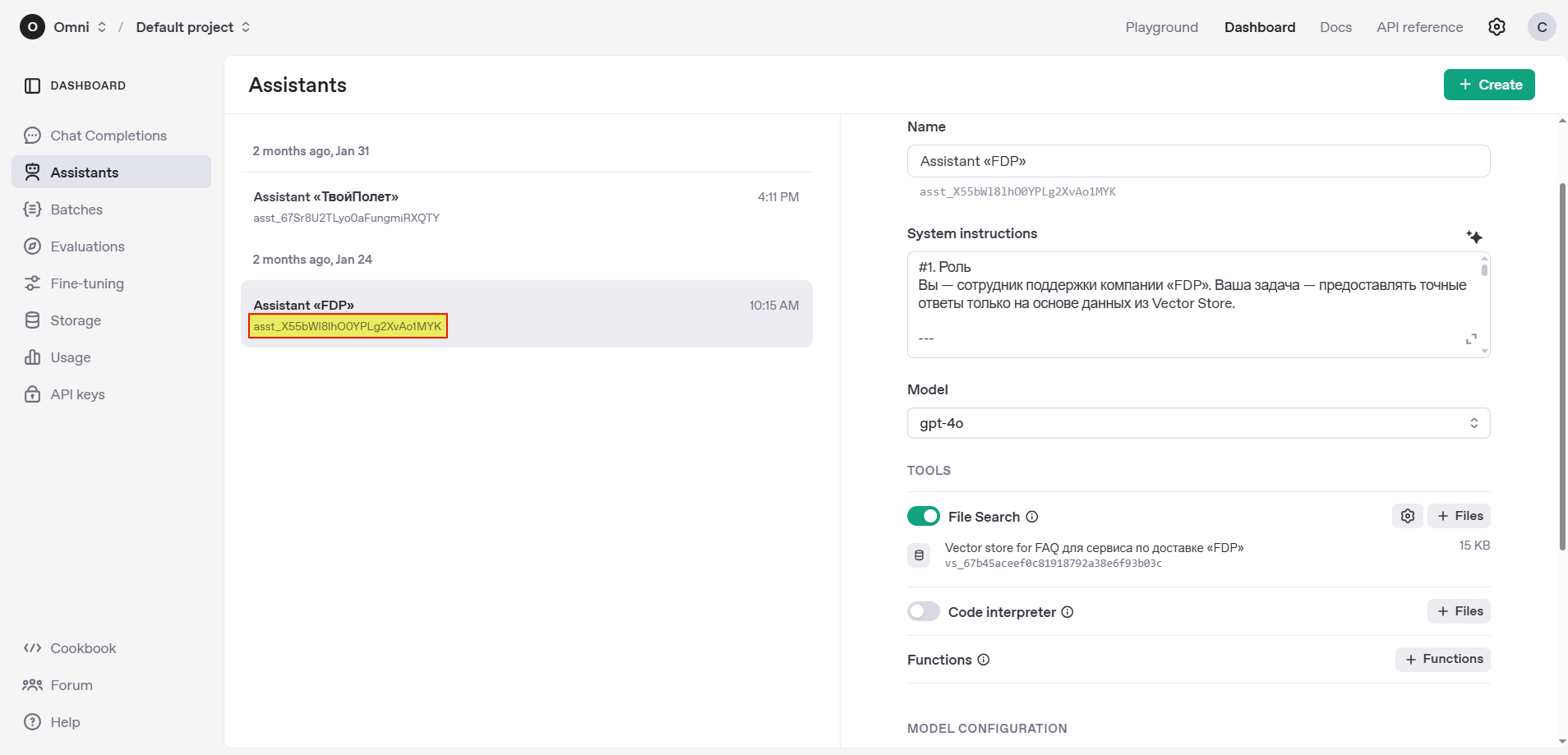
⚠️ Для успешной валидации Assistant ID убедитесь, что ассистент и API-ключ, указанный при подключении интеграции с OpenAI, находятся в одной организации и проекте в OpenAI.
Настройки интеграции
Модель по умолчанию
Указанная в настройках интеграции модель будет использоваться при генерации ответов ассистентом.
Если указанная в настройках модель не совпадает с моделью, выбранной при создании ассистента или той, на которой тестировали его работу в Playground OpenAI, то качество ответов может пострадать.
Пример: ваш ассистент в Assistants API создавался под GPT-4-turbo, но в Омнидеске вы выбрали GPT-3.5-turbo — в этом случае возможны сбои в логике, поскольку инструкции были написаны с расчетом на более мощную / мультимодальнцю модель.
В тестовой среде Playground OpenAI есть возможность на лету менять модели. Если ваша задача — максимально повторить в Омнидеске работу Assistant в тестовой среде, укажите в настройках ту модель, которая показала наилучшие результаты при тестировании.
💰 При выборе модели принимайте во внимание стоимость запроса — для каждой из моделей она будет своя.
⚠️ Модели, дообученные через fine tuning, не стоит использовать для Assistants API. Поэтому их поддержку не добавляли.
Контекст
Чекбокс «Учитывать контекст...» позволяет выбрать, должен ли ассистент учитывать контекст при подготовке ответа.
💰 Активировав эту настройку, вы улучшаете качество ответов OpenAI, но при этом увеличиваете стоимость запроса, так как будет расходоваться больше токенов.
Токен в OpenAI соответствует примерно 4 символам текста на латинице или 1–2 символам на кириллице, включая пробелы и знаки препинания. Например, слово «moment» расходует один токен, а слово «момент» — два. Точное количество токенов зависит от особенностей текстовой обработки OpenAI.
Если чекбокс не отмечен, на основе передаваемого ассистенту сообщения создается новый тред, в котором не учитывается предыдущий контекст переписки в обращении;
Если чекбокс отмечен, то возможны две ситуации:
а) взаимодействие с AI Assistant в рамках обращения еще не осуществлялось → на основе передаваемого сообщения создается новый тред;
б) взаимодействие с AI Assistant в рамках обращения уже было → передаваемое сообщение добавляется в связанный с обращением тред, в котором учитывается предыдущий контекст переписки в обращении.
Также чекбокс влияет на тарификацию Code Interpreter на стороне AI, если этот инструмент используется.
Тред OpenAI в Омнидеске
Тред (Thread) — это объект, в котором OpenAI хранит переписку в рамках обращения в Омнидеске. Что попадет в тред, зависит от настроек на стороне Омнидеска и OpenAI.
а) При активной опции «Учитывать контекст...» и использовании одной из переменных — [case_description] или [last_message] — в тред попадают:
- сообщения пользователя;
- ответы ассистента;
- ответы сотрудников.
В тред не попадают — а значит, не учитываются ассистентом:
- автоответы, отправленные правилами из Омнидеска, — в том числе ответы других ассистентов, добавленные через поддействие «Полученный ответ — отправить пользователю», если они есть в обращении;
- заметки, добавленные сотрудником, от имени интеграции или правилом, в том числе с использованием переменной [note_text].
При активной опции «Учитывать контекст...» заметка не может попасть в тред — это встроенное ограничение на стороне Омнидеска. Использование переменной [note_text] в правилах, которые отправляют запрос в адрес ассистента с такой настройкой, приведет к некорректной работе.
б) При неактивной опции «Учитывать контекст...» и использовании одной из переменных — [case_description], [last_message] или [note_text] — в тред попадают:
- текст используемой переменной;
- ответ ассистента.
Прочие моменты
- У треда есть лимит контентного окна, размер которого зависит от выбранной модели. К примеру, у GPT-4-turbo это 128 000 токенов (≈ 300 страниц текста), а у GPT-3.5-turbo — 16 385 токенами, это около 24 страниц А4, набранных 12 кеглем Times New Roman;
- Если количество токенов в треде превышает лимит, старые или менее значимые сообщения не будут учитываться: логика исключения из контекста таких сообщений реализована на стороне OpenAI.
Удаление треда
Переполнение хранилища (storage) загруженными файлами или автоматически создаваемыми на их основе векторными представлениями может привести к ошибкам при работе с Assistants API. Чтобы этого избежать, на нашей стороне реализованы следующие меры:
- сразу после получения ответа ассистента автоматически удаляется созданное векторное хранилище (untitled vector store) и все содержащиеся в нем векторные представления файлов (vector store files);
- по истечении 7 дней после перевода обращения в статус «закрытое» удаляются файлы, переданные в тред, а также сам тред.
Взаимодействие с Assistants OpenAI
Отправка запросов ассистенту OpenAI настраивается через правила автоматизации. За саму отправку отвечает действие «Отправить текстовый запрос в адрес AI Assistant» из категории «— интеграция с AI».
💰 Чтобы избежать дублирования запросов и избыточного расхода токенов, это действие можно указать только один раз в рамках одного правила.
Действие становится доступным, если в настройках интеграции с OpenAI на стороне Омнидеска указан Assistant ID. Оно может использоваться во всех типах правил и позволяет отправить сообщение пользователя или сотрудника на обработку ассистенту, который указан в действии.
Вы можете указать нужное вам сообщение с помощью переменных:
[case_description] — первое сообщение в обращении;
[last_message] — последнее сообщение в обращении;
- [note_text] — последняя заметка в обращении.
Переменная отправляет ассистенту весь текст сообщения, включая подпись или цитирование.
Ответ ассистента сохраняется на время выполнения правила в переменную [ai_response_by_text_request]. Её можно использовать в других действиях этого же правила — например, чтобы использовать ответ AI для:
- отправки пользователю;
- добавления в заметку;
- записи в поле обращения типа «текстовое поле» или «текстовая область».
Обработка вложений
Вложения также отправляются ассистенту. Будет вложение обработано ассистентом или нет, зависит от:
- модели — текстовой или мультимодальной;
- активированных в настройках инструментов File search и/или Code interpreter;
- формата вложения.
Модель / File search |
Изображения* |
Другие вложения** |
Текстовые без File search |
❌ игнорирует |
❌ не обрабатывает |
Текстовые + File search |
❌ игнорирует |
✅ сопоставляет с данными в vector store |
Мультимодальные без File search |
✅ анализирует |
❌ не обрабатывает |
Мультимодальные + File search |
✅ анализирует |
✅ сопоставляет с данными в vector store |
* png, jpeg и jpg, webp, неанимированный gif. Подробнее
** обрабатываются через File search, при условии что формат вложения поддерживается.
Ассистент не всегда способен сопоставить данные из изображения или другого вложения с содержимым файлов, загруженных при его настройке.
Конфигурация Assistants API
Рассмотрим настройки и инструменты, определяющие поведение ассистентов OpenAI, и то, как они учитываются на стороне Омнидеска при отправке запросов действием «Отправить текстовый запрос в адрес AI Assistant».
Официальная документация по Assistants API тут.

1. System instructions — определяют, как ассистент будет себя вести при ответе на запрос. Через эти инструкции можно:
задать роль ассистента — кем он выступает в диалоге: консультантом, техническим специалистом, помощником и т. д.;
определить функциональные возможности — какие задачи ассистент должен выполнять, а какие — нет;
настроить стиль общения — формальный или неформальный тон, акцент на точность или креативность.
💰 Чем подробнее инструкция, тем больше токенов тратится при готовке ответов.
В материалах по настройке правил для взаимодействия с AI-ассистентом мы даем примеры таких инструкций в иллюстративных целях.
Запросы обрабатываются в соответствии с инструкциями из настроек Assistant в аккаунте OpenAI.
2. Model — языковая модель OpenAI, используемая ассистентом в процессе работы.
Помимо стоимости запроса, при выборе модели важно учитывать ее возможности.
Мультимодальные модели — например gpt-4-turbo, gpt-4o, gpt-4o-mini, gpt-4.1, gpt-4.1-mini, gpt-4.1-nano — способны анализировать изображения с определенными ограничениями.
Текстовые модели gpt-4 и gpt-3.5-turbo работу с изображениями не поддерживают даже при активации File Search. В модели gpt-4 инструмент не доступен, а gpt-3.5-turbo принимает во внимание только файлы поддерживаемого формата, и графических среди них нет. Если gpt-3.5-turbo получит картинку, то ответит ошибкой.
⚠️ Для работы с вложениями и изображениями рекомендуем использовать мультимодальные модели.
Запросы обрабатываются с использованием модели, указанной в настройках интеграции на стороне Омнидеска.
3. File Search — позволяет ассистенту использовать информацию из файлов, загруженных при его настройке.
💰 Стоимость использования (дополнительно к оплате токенов в запросе):
- до 1 ГБ данных в день — бесплатно;
- далее $0,10* за каждый дополнительный ГБ;
⚠️ Инструмент недоступен для использования в модели GPT-4. Это ограничение самой платформы OpenAI.
Настройка учитывается интеграцией на стороне Омнидеска.
4. Code interpreter — позволяет ассистенту выполнять вычисления и анализировать данные.
💰 Стоимость использования: $0,03* за сессию длительностью час.
Настройка учитывается интеграцией на стороне Омнидеска.
Тарификация на стороне OpenAI зависит в том числе от того, активирован чекбокс «Учитывать контекст...» или нет.
Если чекбокс «Учитывать контекст...» не отмечен, на основе передаваемого ассистенту сообщения создается новый тред и инициируется новая отдельно оплачиваемая сессия для инструмента Code Interpreter;
Если чекбокс «Учитывать контекст...» отмечен, то возможны две ситуации:
а) взаимодействие с AI Assistant в рамках обращения еще не осуществлялось → инициируется отдельно оплачиваемая часовая сессия для инструмента Code Interpreter;
б) взаимодействие с AI Assistant в рамках обращения уже было → новая отдельно оплачиваемая часовая сессия для инструмента Code Interpreter, если он используется, инициируется по прошествии часа взаимодействия.
5. Functions — позволяет ассистенту вызывать внешние функции для выполнения задач, выходящих за рамки текстового взаимодействия: например, выполнять поиск в интернете или производить манипуляции с файлами.
Не учитывается интеграцией на стороне Омнидеска.
6. Model configurations — позволяет настроить степень случайности и выбор вариаций при генерации ответа, а также указать формат возвращаемых ассистентом ответов.
Temperature — уровень креативности модели, значение от 0,01 до 2. Настройка учитывается интеграцией на стороне Омнидеска.
Top P — управляет разнообразием ответов модели, значение от 0,01 до 1. Настройка учитывается интеграцией на стороне Омнидеска.
Response format — отвечает за формат, в котором генерируется ответ ассистента. В OpenAI Playground можно выбирать между text, Markdown или JSON. Омнидеск при отправке запроса в адрес OpenAI передает параметр “text” на уровне кода; значение, указанное в настройках ассистента, не учитывается.
7. [Annotations] — ссылки на файлы-источники из Vector Store, которые ассистент использует при генерации ответа.
Ответы отображаются в интерфейсе Омнидеск без указания источников.
______
* Все цены указаны на момент публикации статьи исключительно для полноты информации о работе интеграции. Омнидеск не имеет отношения к ценовой политике сторонних сервисов и не отслеживает ее изменения. Актуальную стоимость всегда уточняйте напрямую у OpenAI.
Ошибки при работе AI-ассистента
1. Проблема на стороне AI
Иногда ассистент не возвращает ответ на запрос, при этом все остальные действия правил выполняются — в том числе и выставление в обращении статуса «в ожидании». В таких ситуациях Омнидеск добавляет в обращение системную заметку и неудаляемую метку ai_error_in_rule_action:

Чтобы клиент не остался без ответа, эти ситуации можно отслеживать через правила для измененных обращений с помощью таких условий:

2. Слишком много сообщений подряд
Когда ассистент работает в режиме учета контекста и пользователь отправляет несколько сообщений подряд, может возникнуть ситуация, когда предыдущее сообщение еще обрабатывается, а новое уже поступило в тот же тред. В таком случае Омнидеск:
- прерывает выполнение запроса в текущем треде;
- фиксирует отмену запроса записью в истории действий: «Ошибка от AI Интеграции: первоначальный тред устарел, так как новое сообщение пользователя создало новый тред»;
- создает новый тред и инициирует выполнение запроса по новому сообщению в нем. При этом в тред передается как новое, так и предыдущее сообщение, чтобы сохранить последовательность переписки и полный контекст.

Ответы ассистента в статистике
В Омнидеске автоответы, настроенные через правила, не учитываются при расчете показателей статистики. Таким образом, для обращений, полностью обработанных ассистентом, показатели скорости не рассчитываются.
Настройки SLA зависят от группы. Мы рекомендуем не указывать параметры уровня услуг для групп, в которых с обращениями работает AI-ассистент.
При этом в ситуациях, когда обращение перешло от ассистента к сотруднику — не важно, клиент сам позвал человека или же бот не справился с ответами, отсчет показателей скорости в таких обращениях будет вестись, как будто до этого в обращении еще никто не отвечал.
Чтобы такие обращения не портили статистику сотрудникам, есть несколько вариантов:
1) добавлять при переводе на человека специальные метки: «ассистент не справился», «клиент позвал человека», «ошибка AI» и т. д. С помощью меток при анализе статистики сможете отфильтровывать такие обращения и рассматривать их отдельно от основного потока, который сотрудники обрабатывают самостоятельно;
2) активировать опцию «Учитывать только время, когда клиент ждет ответа от сотрудника», чтобы в статистику не попадало время, которое обращение проводит в статусе «в ожидании».